Cross post with Hands On Sql
Eliminate File Sort for Fast Queries
When SQL performs queries sometimes it needs to break down the work into intermediate steps saving the result, in order to do further filtering. It seems counterintuitive but it’s often faster than if SQL were to do the join for each row 1 by 1. This is often the case with poorly indexed joins or inefficient layouts.
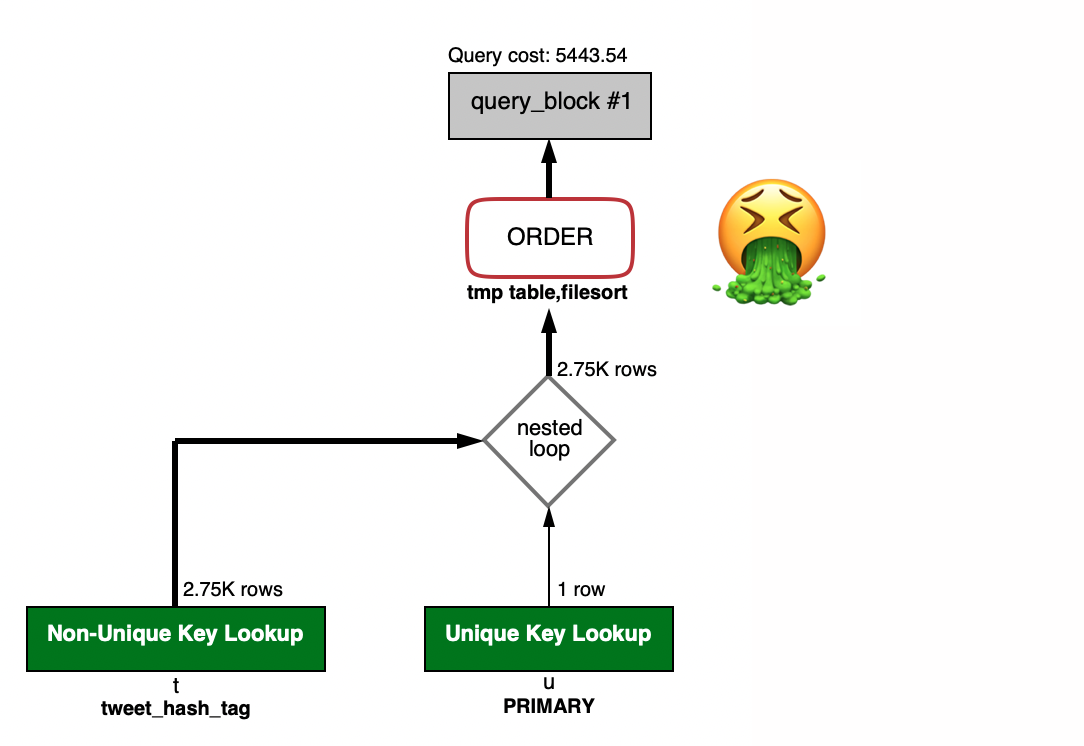
When a query reaches a particular difficulty or size you will see Using index; Using temporary; Using filesort in the explain for the query. This can be particularly bad for large datasets where it can cause lots of disk IO. I’ve even seen it bring a server to its knees by exhausting the Amazon RDS IOPS credit.
Example
Consider the situation where we have users and tweets. We are trying to list the newest users with a tweet about a particular hash tag.
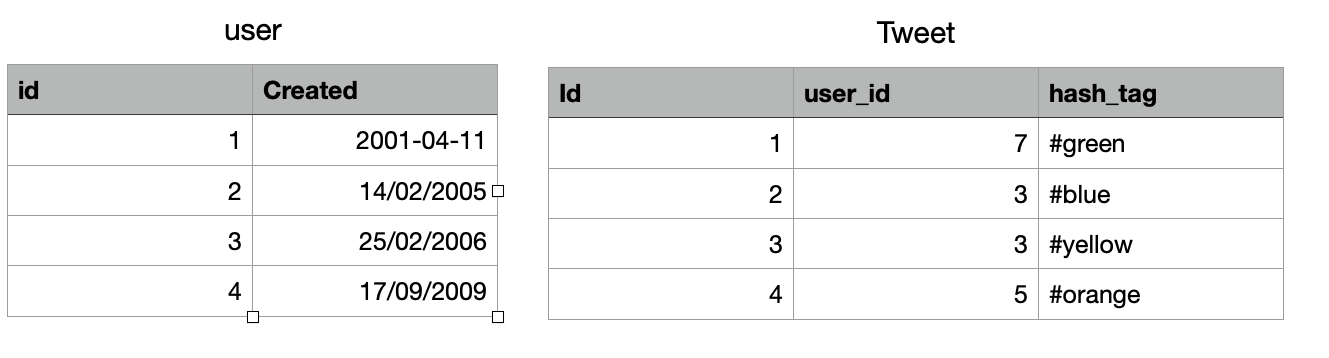
create table user(
id int primary key auto_increment,
created datetime,
index user_created (created)
);
create table tweet(
id int primary key auto_increment,
hash_tag varchar(255), -- only one per tweet
user_id int not null,
foreign key (user_id) references user(id),
index tweet_1(hash_tag, user_id)
);
The query would be like this.
select u.* from user u
join tweet t on t.user_id = u.id
where t.hash_tag = @particular_hash_tag
order by u.created desc limit 10;
In this example we have 1 million users, 1 million tweets with 1000 hash tags, and an even distribution between them.
In the explain for the query we see the plan has the dreaded Using index; Using temporary; Using filesort.
The Reason
This is because the data is being filtered on one side of the join and sorted on the other.. We only need the last 10 user but it needs to filter all of the tweets’s and join them to find out what to sort.
If we could have an index across both tables or have the filter and sort on the same table then we can get that sweet Backward index scan performance.
In some databases like Postgres you can use materialized views to achieve this. In others you need to change the data or change the query to make it easier for SQL.
By changing the data we need to copy the user.created field into the tweet table.
So we can write a query like this.
select u.* from user u
join tweet t on t.user_id = u.id
where t.hash_tag = @particular_hash_tag
order by t.created desc limit 10;
It is annoying that you need two copies of the created field. One way to keep the field up to date would be with triggers.
Luckily there is another property we can use to make the query easier. Because our database is using incrementing primary keys we can use the user_id as a proxy for created in the sort. Whats great about this, is that its already in the tweet table &indexed. So the filtering and sorting can be done quickly in one index.
For example
select u.* from user u
join tweet t on t.user_id = u.id
where t.hash_tag = @particular_hash_tag
order by t.user_id desc limit 10;
Now the optimized query can much faster. For this data set of 2 million rows, it goes from 20ms to 0.5ms, almost two orders of magnitude. In production systems I’ve seen the query go from minutes to a few milliseconds.