I've been looking at ways to organize a document set. Im particularly interested in comparing and clustering documents based on their content. In these experiments a test set of Wikipedia documents, most of the documents come from a keyword search about fish with some random ones to mix it up.
For comparing these documents I’ve used the categories taken from wikipedia and mined the important words. Each document can belong to multiple categories. Often these are subject categories but sometimes they just serve to help the structure of wikipedia. The important words (judged my TF-IDF) are words that define the content of the document, these are good keywords.
For comparing these documents I’ve used the categories taken from wikipedia and mined the important words. Each document can belong to multiple categories. Often these are subject categories but sometimes they just serve to help the structure of wikipedia. The important words (judged my TF-IDF) are words that define the content of the document, these are good keywords.
keyword search
Often keyword search is the only way to browse a document set, this is bad because keywords can be ambiguous, people can accidentally choose bad keywords and not know when they have.
Description
I've chosen to display this document set in a node graph where the relationships between objects can clearly be seen. The tools used are Arbor.js and Canvas. Arbor.js is a javascript library that creates a weighted gravity node graph. One of the useful effects of a weighted graph is that connected nodes become close to each other while other nodes are pushed away. Canvas the HTML 5 element draws the graph. Using Canvas I’ve been able to hide parts of the graph that I don’t want to display and make them available when the user moves their mouse over top of connected nodes. The way this is done make the relationships between documents stand out clearly.
Document First approach (m2)
The wikipedia documents shown as the red nodes always visible. With the metadata nodes (important words & categories) as hidden nodes. When a user moves the mouse over a document node all of that documents metadata nodes become visible, showing if any are related to other documents. The space between nodes shows how different or similar they are. This comes from the physics in Arbor.js moving connected nodes together and other nodes away.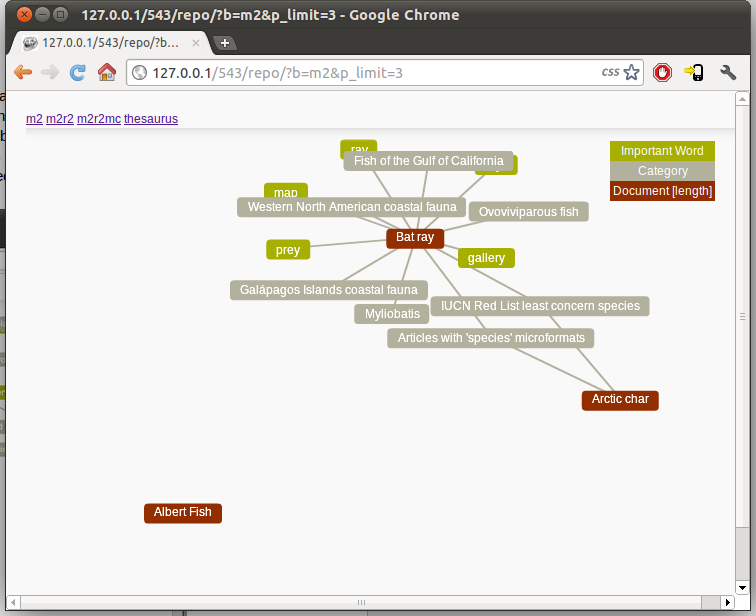 |
| Figure 1 |
Metadata First approach (m2r2mc)
The metadata nodes are shown first with the document nodes hidden. Related nodes will be close together with unrelated nodes far apart. When a Node is hovered over the connected document node(s) become visible. The length of a node is shown to the side of the document name. When a user clicks on a node that gets selected as a facet.When a user clicks on a metadata node it becomes selected as a facet and filters the nodes accordingly. When a user clicks on a document node they are taken to the wikipedia page of that document.
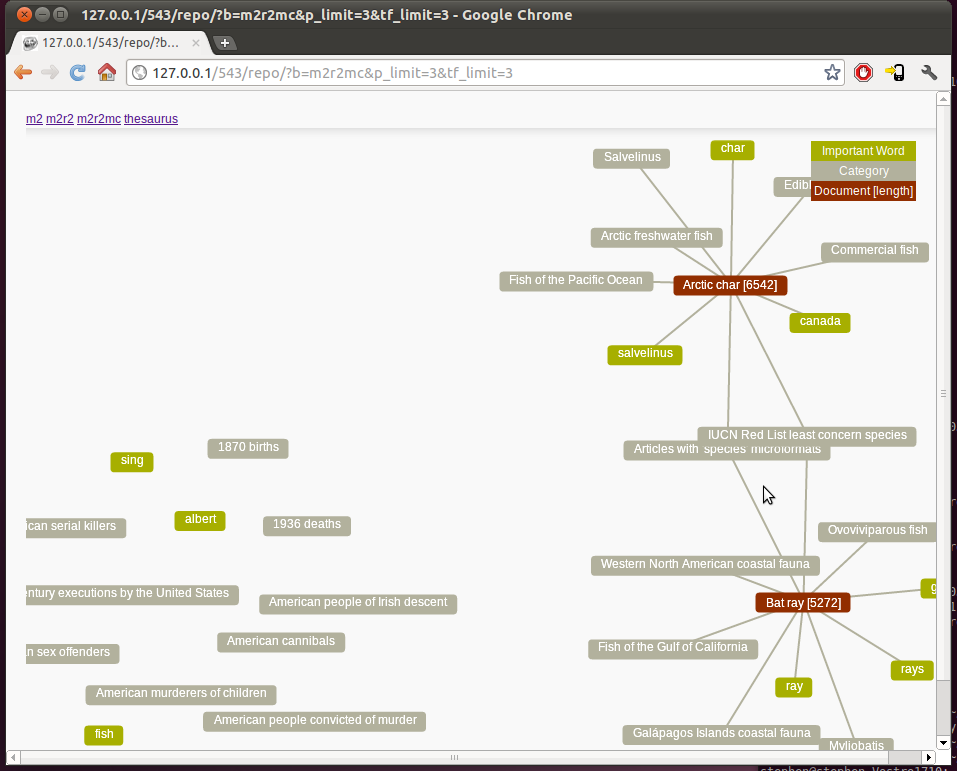 |
| Figure 2 |
Sometimes a user will choose a bad facet and filter items that they want, with traditional document set visualisations its unclear to the user that they’ve made the mistake. One of the strengths of this method is a user can see if they're about to choose a good facet, because the related items will become visible. The user might see that they’re about to choose a bad filter and see a better one near by.
One documents length does not relate to other documents. So this is presented just a text beside the document name. This doesn't take advantage of the graph nature of this presentation. It would be nice to present the length as the node size, but due to lack of time this couldn't be implemented.
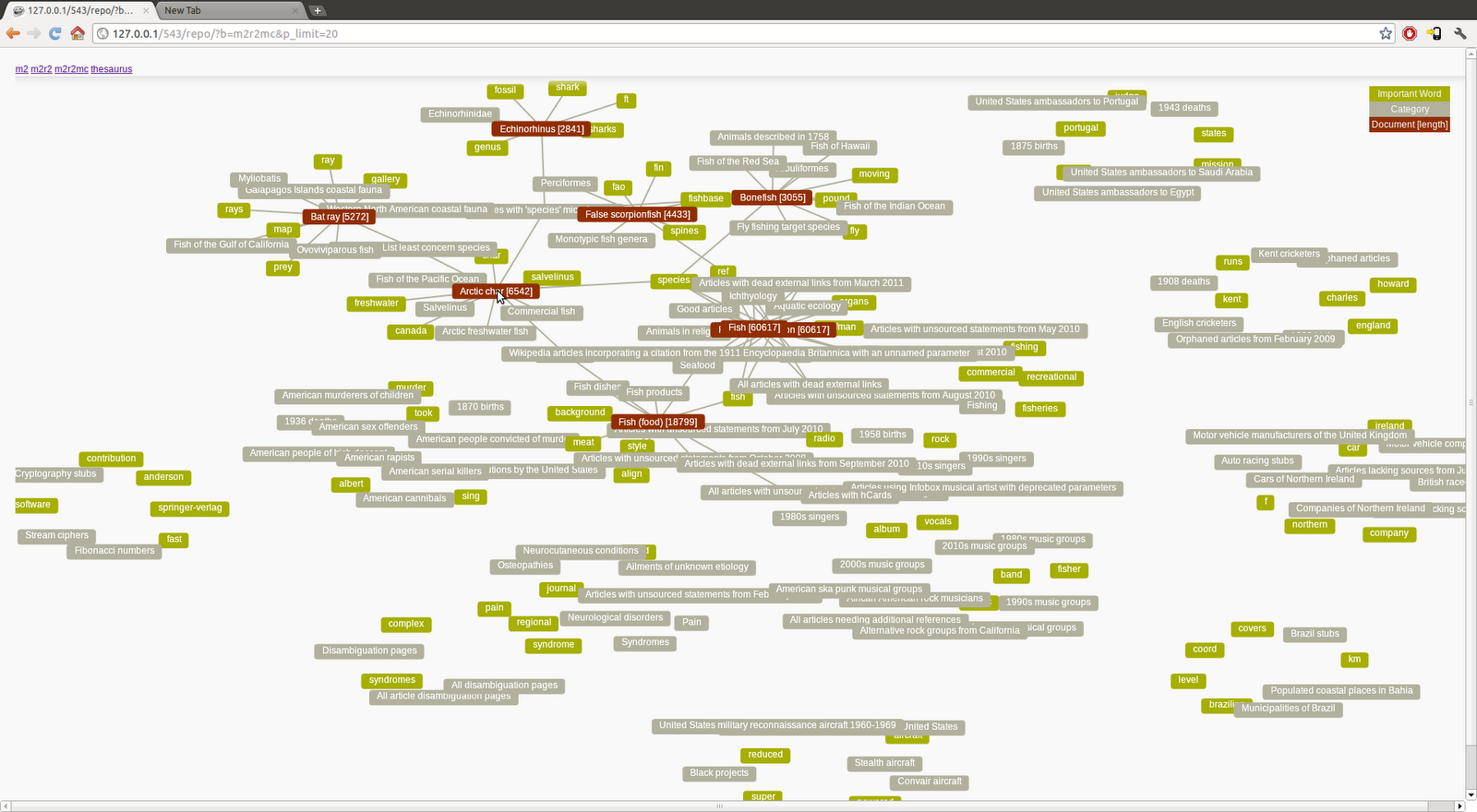 |
| Figure 3 |
Its possible to limit the number of shown “important word” nodes, because they are ordered you can choose to show only the top 3,4 or 15. This has only been implemented with a php get option tf_limit=X where X is a number. It would be difficult to do the same with the categories.
When limiting the amount of metadata nodes the similarities and differences between documents become less clear. This is an area for further research, it falls back on how good the important words are. In a small document set like the one used in this assignment its possible for unimportant words to have a high TF-IDF value, but with bigger datasets unimportant words should become less of a problem.
Figure 3 also shows 2 levels of connectedness with the document nodes, which are usually hidden. This makes it clearer what documents are related to each other.
Future work
It'd be cool to implement this all in javascript parsing the wikipedia pages on the fly. So the user can put in a keyword and compare the results, or the user could put in one wiki page and compare all linked to documents.
For a live example check out stephenn.info/p/comp543 this might kill your brower, its pretty heavy.